Symbol Files & Build Ids
Introduction
After your build system completes a build, it produces several artifacts. One of these is a Symbol File. This file contains your compiled code and important debug information used by Memfault. ELF is the format most commonly used to produce this file (AXF is another commonly encountered format). Some common file extensions of symbol files are:
.elf.axf.out
In order to fully process uploaded data, such as coredumps, Memfault needs to locate the Symbol File (ELF/AXF) that corresponds to the software that produced the uploaded data. Without an exact match, Memfault will not be able to decode the uploaded data. Processing will still happen, but the resulting Trace will contain limited information until the symbol file is uploaded and the data is reprocessed.
To that end, the SDK adds metadata to the uploaded data to identify the software that produced the data. Likewise, any Symbol File that is uploaded to Memfault must have that same identifying metadata.
Identifier Types
There are 3 types of identifiers:
| Memfault Build Id | GNU Build Id | Software Type & Version | |
|---|---|---|---|
| Example | a1e688... | a1e688... | wifi-fw/1.0.0 |
| Automatically generated hash | ✅ | ✅ | |
| Manually chosen | ✅ | ||
| Compiler requirement | GNU/gcc | ||
| ID embedded inside ELF/AXF | ✅ | ✅ | |
| ID passed manually upon Symbol File upload | ✅ | ||
| Requires running Python script to post-process ELF/AXF | ✅ |
We recommend using either the Memfault Build Id or GNU Build Id option. The Build Ids are automatically generated based on the contents of the ELF/AXF file.
Software Type & Version identifiers are manually assigned and therefore error-prone.

When uploading a Symbol File (ELF/AXF) that has a Build Id embedded, it is possible to add a Software Type & Version based identifier, in addition to the embedded Build Id. This will link the Symbol File with the Software Version. That way, you can later look up and download the Symbol File by Software Type and Version through the Software Versions UI in Memfault.
Note that for the purpose of finding a Symbol File to match uploaded data, the Build Id always takes precedence over Software Type & Version.
Adding Build Ids
Memfault has two ways to add a Build ID to a target. Select the appropriate one below based on your toolchain setup.
- GNU Build Id Linker Flag + Snippet
- Memfault Build Id Python Script
Requires use of the GNU GCC or Clang compiler.
- Add
-Wl,--build-id=sha1to flags passed to linker via GCC/Clang - Add
#define MEMFAULT_USE_GNU_BUILD_ID 1tothird_party/memfault/memfault_platform_config.h - Add the following snippet to your projects linker script (
.ldfile) where "<YOUR_FLASH_SECTION>" below will match the name of the MEMORY section that read-only data and text is placed in.
.note.gnu.build-id :
{
__start_gnu_build_id_start = .;
KEEP(*(.note.gnu.build-id))
} > <YOUR_FLASH_SECTION>
Be sure to update <YOUR_FLASH_SECTION> to match the name of the section
.text is placed in!
The .note.gnu.build-id output section name is used to locate the Build ID when
the symbol file is uploaded. The __start_gnu_build_id_start identifier is used
at compile time by the SDK for populating the Build ID.
See the FreeRTOS example app in the Memfault SDK for a reference implementation!
Update your build system to invoke the scripts/fw_build_id.py script on your
ELF as part of a post-build step.
For example, using CMake, this can be achieved by adding a custom command to the target:
add_custom_command(TARGET ${YOUR_EXECUTABLE_NAME} POST_BUILD
COMMAND python ${MEMFAULT_SDK_ROOT}/scripts/fw_build_id.py ${YOUR_EXECUTABLE_NAME}
)
The script depends on pyelftools so make sure you have run
pip install pyelftools or added it to your requirements.txt
See the ESP32 example app in the Memfault SDK for a reference implementation!
For projects using IAR EWARM, see the instructions below for adding a post-build
action: Install Python (eg python3.9 from the Microsoft app store) Install the Then add the appropriate post-build action, for example: The Output Converter utility runs before the post-build actions, so it will
always generate output with a missing Build Id. Instead, invoke Additionally, Build Actions in IAR EWARM are batched, so to ensure Memfault
Build Id insertion and binary output conversion execute in the proper order,
invoke a separate script wrapping calls to Details
pyelftools Python package by:
python3.9.exe -m pip install pyelftools==0.27ielftool
after Memfault Build Id insertion to ensure the binary has a Build Id. Refer
to the
IAR EWARM Manual (PDF warning)
for more information on using ielftool.fw_build_id.py and ielftool.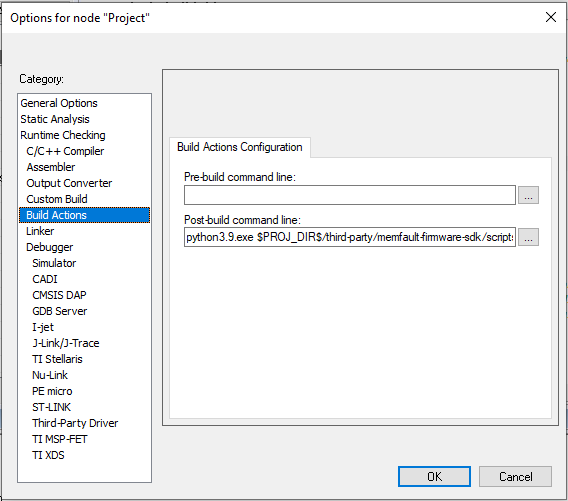
Uploading Symbol Files using Memfault CLI
Please follow the instructions to install the Memfault CLI tool first.
Uploading Symbol File with Build Id
Because the Build Id is embedded inside the ELF/AXF file, the Build Id is
automatically recognized and extracted and does not need to be passed as an
argument to the memfault tool:
memfault --org-token $ORG_TOKEN --org acme-inc --project smart-sink \
upload-mcu-symbols \
build/symbols.elf
If you are using Link-Time Optimization in your build, you may get an error when uploading the symbol file
Using
link-time optimization (-flto)
can cause the symbol upload to fail:
ERROR: main-with-lto.elf: Build Id missing. Specify --software-version and
--software-type options or add a Build Id (see https://mflt.io/symbol-file-build-ids)
Usage: memfault upload-mcu-symbols [OPTIONS] PATH
Error: Upload failed!
-flto may inline the contents of the Build ID variable, removing the symbol
from the executable. To work around this, add the appropriate flag to the linker
args:
- GCC:
-Wl,--require-defined=g_memfault_build_id - Clang:
-Wl,--undefined=g_memfault_build_id,--no-undefined
Uploading Symbol File with Software Type & Version
To associate a Software Type & Software Version with a Symbol File, the
--software-type and --software-version arguments need to be passed to the
memfault tool.
Optionally, a --revision (Git commit hash, SVN revision, etc) can be passed as
well to store the version control revision in the newly created Software
Version.
memfault --org-token $ORG_TOKEN --org acme-inc --project smart-sink \
upload-mcu-symbols \
--software-type stm32-fw \
--software-version 1.0.0-alpha \
--revision 89335ffade90ff7697e2ce5238bd4c68978b6d6e \
build/symbols.elf
Frequently Asked Questions
When using a Build ID, is it okay if there is not always a 1:1 mapping with Software Version?
Yes, in fact this is one of the benefits of using Build IDs. In this scenario there will always be a 1:1 mapping between the binary running and a Build ID so Memfault is guaranteed to recover accurate stack traces while at the same time giving you flexibility around how you report software versions.
Two common situations where there is not a 1:1 mapping are the following:
- "Dev" builds -- Memfault recommends using semver and for pre-release debug builds, using a common software version (i.e 1.1.1-dev). This way all the crashes and issues observed during debug get bucketed under a single version that's easy to track in the UI. In this situation you wind up with many separate Build ID mapping to a single Software Version
- In some systems, multiple Software Versions can map to the same Symbol File (via Build ID), because the Software Version in the device is not stored within the application binary, so it does not impact the Symbol File (and corresponding Build ID).