Alerts
The Alerts feature will send a notification when monitored Devices satisfy a given condition.
| Alert Type | Trigger | Polling Frequency |
| Fleet Threshold Alert | Fleet-wide aggregation of a timeseries metric meets a condition | Hourly |
| Device Threshold Alert | Metric value in a received report meets a condition | N/A - evaluated immediately when metric report is received |
| Device Offline Alert | Device no longer checking in with Memfault | Every 5 minutes |
| Reboot Alert | Device or fleet reboot count meets a condition | Evaluated when reboot data is received |
Fleet Threshold Alerts
Fleet Threshold Alerts operate on aggregate Metrics conditions. For example, you
could configure a Fleet Threshold Alert that triggers when your production
Cohort surpasses a mean count of 5 connection failures in a time window of one
hour.
Only Metrics marked as Timeseries can be used in the condition for Fleet Threshold Alerts.
Fleet threshold alerts are evaluated every hour. You will receive a notification if the aggregate meets the condition for data points in the preceding hour.
Device Threshold Alerts
Device Threshold Alerts trigger when any Device reports a certain value or range of values for a Metric.
Any type of Metrics can be used in the condition for Device Threshold Alerts.
Whenever the Memfault cloud receives a Heartbeat event with metrics from a Device, it will evaluate the applicable Device Threshold Alerts and create Incidents, if triggered. Depending on the configuration of the Alert, notifications can be sent immediately as an Incident starts, or as a scheduled summary of new Incidents.
Incident creation and resolution
The creation and resolution of an incident is controlled by the creation (incident start) and resolution (incident end) delays in the alert configuration. You can use these values to reduce incident noise.
-
The incident start delay is the time that must pass before an incident is declared after the metric condition is met.
For example, if a value sometimes briefly goes above the threshold but goes back to normal within an hour, you can set the alerting delay to 1 hour 30 minutes to avoid creating an incident for a brief spike.
An incident will only be created if either another matching value comes in after the start delay has passed, or if no data is received for at least the start delay period.
When an incident is created, it will appear as ALERTING in the incident list.
-
The incident end delay is the time that must pass before an incident is resolved after the metric condition is no longer met.
For example, if you see that your alert frequently gets resolved and then starts firing again shortly after, you can set an end delay to keep the incident in the "ALERTING" state unless a new value comes in after the end delay has passed.
Unlike in the case of the start delay, if a Device reports no new data, the incident will stay in the ALERTING state until a new value comes in.
Once the incident is resolved, it will appear as RESOLVED in the incident list.
For alerts that were created before the availability of the delay feature, you should see "No delay" for the start delay, and an end delay of 1 day. This is to match previous behaviour where all alerts had a maximum of 1 incident per 24 hour period. Please set this to a reasonable value for your specific alerts.
Incident start and end delays illustrated
Basic example
Here's an example of an alert with a start delay of 15 minutes and an end
delay of 30 minutes. The metric threshold is set to battery_discharge > 50.

-
At (a) 0:30 h, a value above the threshold is captured, but the incident is not created yet. A new value below the threshold is captured at 0:45 h, so this momentary spike is ignored.
-
At (b) 2:15 h, another value above the threshold is captured. Another above-threshold value comes in at 2:30 h, which is when the incident is created. This is because the start delay of 15 minutes has passed.
If you enable "notify: when an incident starts", the configured targets will be notified when this value is received by Memfault.
-
At (c) 3:00 h, a value below the threshold is captured. The incident is not resolved yet, because the end delay of 30 minutes has not passed, and a new value above the threshold is captured shortly after, keeping the incident in the ALERTING state.
-
At (d) 3:30 h, another value below the threshold is captured. The incident is resolved when an additional below-threshold value is captured at 4:00 h, because the end delay of 30 minutes has passed.
If you enable "notify: when an incident is resolved", the configured targets will be notified when this value is received by Memfault.
When no data is received
In this next example, we illustrate what happens when no data is received by Memfault.

-
This is similar to the previous example at first, but after the event at (b) 2:15 h is captured, the Device stops sending data for a while (for example, because it was shut down for a while).
-
In this case, an incident is automatically created after the start delay has passed since the receipt of the last value, i.e. 15 minutes for this alert (the difference between capture and receive time is explained below).
-
Note that the incident is not automatically resolved after the end delay of 30 minutes has passed. This is because no new data has been received confirming that the Device was behaving as expected.
-
When the Device is seen again at (c) 4:15 h with a value below the threshold, the incident is resolved as it has been more than 30 minutes since the (b) 2:15 h value.
Capture vs. Receive Time
Your Devices may report data in realtime or near-realtime, in batches, or with significant latency. To handle a diverse set of Device Heartbeat intervals, incident start and end delays are calculated based on the capture timestamp and not the received timestamp, except in the following cases:
-
If no data is received after a value that crosses the threshold (like in the example above), the start delay is evaluated based on the last received timestamp, and an incident is automatically created once it has passed.
-
If Devices send timestamps in the future, they are treated as if they were captured at the time of receipt.
-
If no capture timestamp is set, the received timestamp is used instead.
-
Additionally, if data is received out of order, any values that are received with a capture timestamp before the last received timestamp are ignored.
In any case, setting a start or end delay shorter than the Heartbeat or batch interval of the Device would behave similarly to setting no delay at all. A good rule of thumb to prevent noise is to use a delay, at minimum, slightly longer than the Heartbeat interval.
By default, events captured by the MCU SDK are timestamped when they're uploaded to Memfault (on Linux and AOSP, events are always timestamped on-device using the Device's RTC clock). This works well for frequently-connected Devices, but for Devices that batch-upload many Heartbeats at once, this would result in all of the events in a batch being timestamped with the same timestamp. You can set an event timestamp using the MCU SDK.
The default MCU Heartbeat interval is 3600 seconds (1 hour). Look at the MCU metrics docs for more context.
Creating a Device Threshold Alert
Let's create an alert when the battery_perc (battery percentage) is below 5%,
for Devices with serial numbers starting with MFLT.
- Click Alerts in the sidebar, and Create Alert in the top right.
- Provide a Title and optional Description (highly advised)!
- Select "Device Threshold" as the Alert Type.
- Set a Condition value from a list of Heartbeat metrics, or type the string
key to find it.
- We set the condition value to is less than 5.
- We also wanted to make sure that the Device Serial values start with
MFLT. - To do this we click (+) and condition, and specify these values.
- Next choose which targets should receive these Alerts. Optionally, click "Manage targets" to navigate to the settings page to manage your targets.
- Next, optionally set up incident start and end delays. Look at the section above for more details.
- Finally, specify when to receive notifications for these alerts.
- To be notified as soon as an incident is created, select "when a new incident starts". Please note that the incident creation depends on the alerting delay.
- To be notified immediately when the alert is resolved, select "when an incident is resolved". Please note that the incident resolution depends on the resolution delay.
- To receive a summary of new & active incidents, select "a scheduled summary
of incidents..." and set up your preferred schedule.
- The timezone is prefilled according to your browser or custom timezone, but you can modify it as you need.
- You can have a minimum of 1 and a maximum of 4 summary schedules configured per alert.
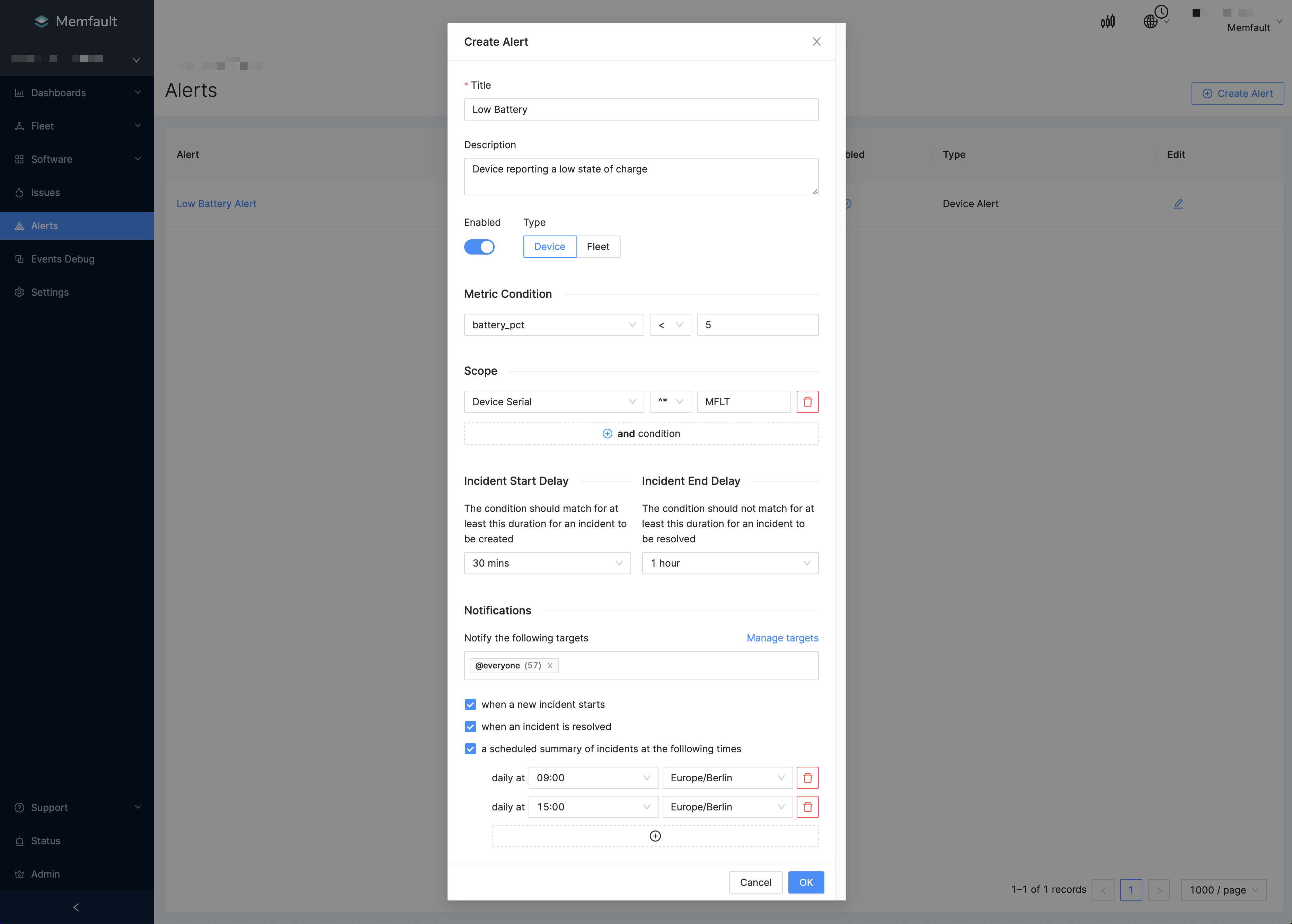
- Above, we have set up our Alert! Click OK to create it.
Device Offline Alerts
Device Offline Alerts trigger when any Device in a set of monitored Devices stops checking in with Memfault (i.e., upload data from the Device SDK to the Memfault cloud).
Incident creation and resolution
This type of Alert is evaluated every 5 minutes: for each Device in the set of monitored Devices, Memfault checks whether the Device has checked in within the allowed time window.
The creation and resolution of an incident is controlled by the creation (incident start) and resolution (incident end) delays in the alert configuration. You can use these values to reduce incident noise.
- The incident start delay is the time that must pass before an incident is declared after a Device has stopped checking in.
For example, if Devices are configured to check in with Memfault every hour, you should set the start delay to at least 1 hour, otherwise incidents will continuously be created and resolved shortly thereafter. In other words, ensure that: expected checkin interval < start delay.
When an incident is created, it will appear as ALERTING in the incident list.
- The incident end delay is the period during which a Device must keep checking in before an incident is resolved.
For example, if you see that your alert frequently gets resolved and then starts firing again shortly after, set an end delay. This keeps the incident in the "ALERTING" state and only resolves it if the Device has been checking in for at least the end delay period.
Once the incident is resolved, it will appear as RESOLVED in the incident list.
Note that because the Device Offline Alerts are evaluated every 5 minutes, the
maximum latency in the detection of a Device going offline is
(incident start delay + 5 minutes).
Incident start and end delays illustrated
Basic example
Here's an example of an alert with a start delay of 1 hour and no end delay.

- Device Offline Alerts are repeatedly evaluated, every 5 minutes (a). The gray vertical lines represent the evaluation intervals.
- At (b) 0:22 h, the Device checks in with Memfault, but falls silent after this.
- At 1:22 h, the start delay of 1 hour (c) has passed. However, the alerts are only evaluated again at 1:25 h, which is when the incident is created.
- Because of the 5-minute evaluation interval, an error of +3 minutes was introduced (d), making the effective start delay 1 hour and 3 minutes.
- At (f) 1:36 h, the Device checks in again.
- At 1:40 h, the alerts are evaluated again, and the incident is resolved after 15 minutes (e) because the Device has checked in again.
- Even though no end delay had been configured, there was an actual delay to resolving (+4 minutes) due to the 5-minute evaluation frequency.
End delay example
Here's an example of an alert with a start delay 1 hour 30 minutes and an end delay of 2 hours. For the sake of simplicity & brevity, the time grid has been removed.

- An incident had already been created before the start of the diagram.
- At (a), the Device checks in with Memfault. The incident is not resolved yet, because the end delay of 1 hour 30 minutes has not passed.
- The start delay (b) has lapsed again, but no checkin has happened in the meantime (c): the incident stays in the ALERTING state.
- At (d), the Device checks in again. Before the start delay lapses again, the Device checks in again at (f).
- The incident is resolved after the end delay (e): the end delay of 2 hours has now passed, while the Device kept checking in.
Creating a Device Offline Alert
Let's create a Device Offline Alert for all Devices in Cohort "Production". The Devices are expected to be checking in every hour. Let's use a start delay of 2 hours and end delay of 4 hours, because it's possible Devices go offline briefly due to spurious periods of network unavailability.
- Click Alerts in the sidebar, and Create Alert in the top right.
- Provide a Title and optional Description (highly advised)!
- Select "Device Offline" as the Alert Type.
- Click "Select Devices". Add the "Current Cohort" filter and add "Production". Click Apply.
- Next, set up incident start and end delays. Look at the section above above for more details.
- Finally, specify when to receive notifications for these alerts.
- To be notified as soon as an incident is created, select "when a new incident starts". Please note that the incident creation depends on the alerting delay.
- To be notified immediately when the alert is resolved, select "when an incident is resolved". Please note that the incident resolution depends on the resolution delay.
- To receive a summary of new & active incidents, select "a scheduled summary of incidents..." and set up your preferred schedule.
- The timezone is prefilled according to your browser or custom timezone, but you can modify it as you need.
- You can have a minimum of 1 and a maximum of 4 summary schedules configured per alert.
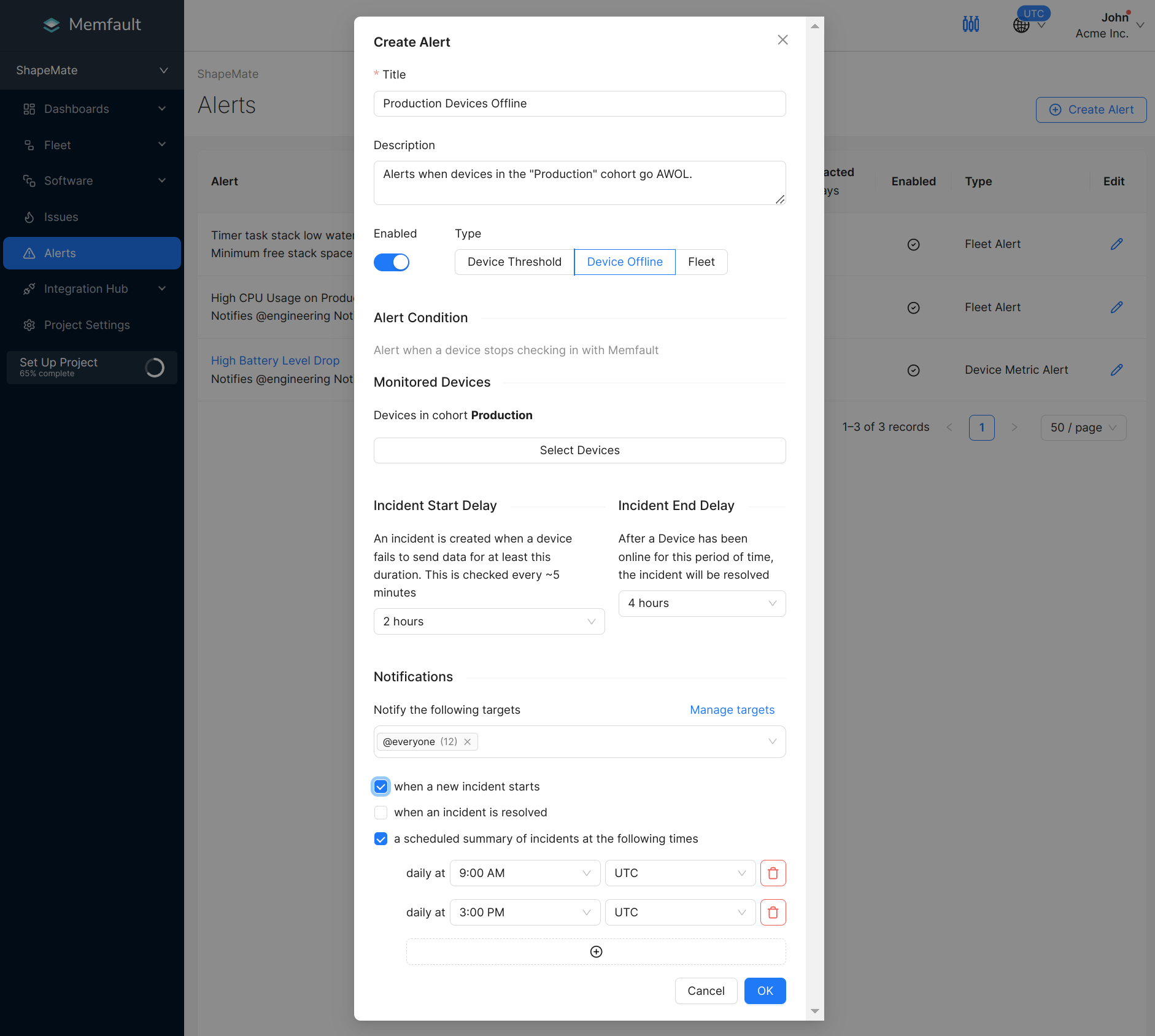
- Above, we have set up our Alert! Click OK to create it.
Reboot Alerts
Reboot Alerts notify you when devices or fleets exceed reboot thresholds. They are available across MCU, Linux, and Android platforms.
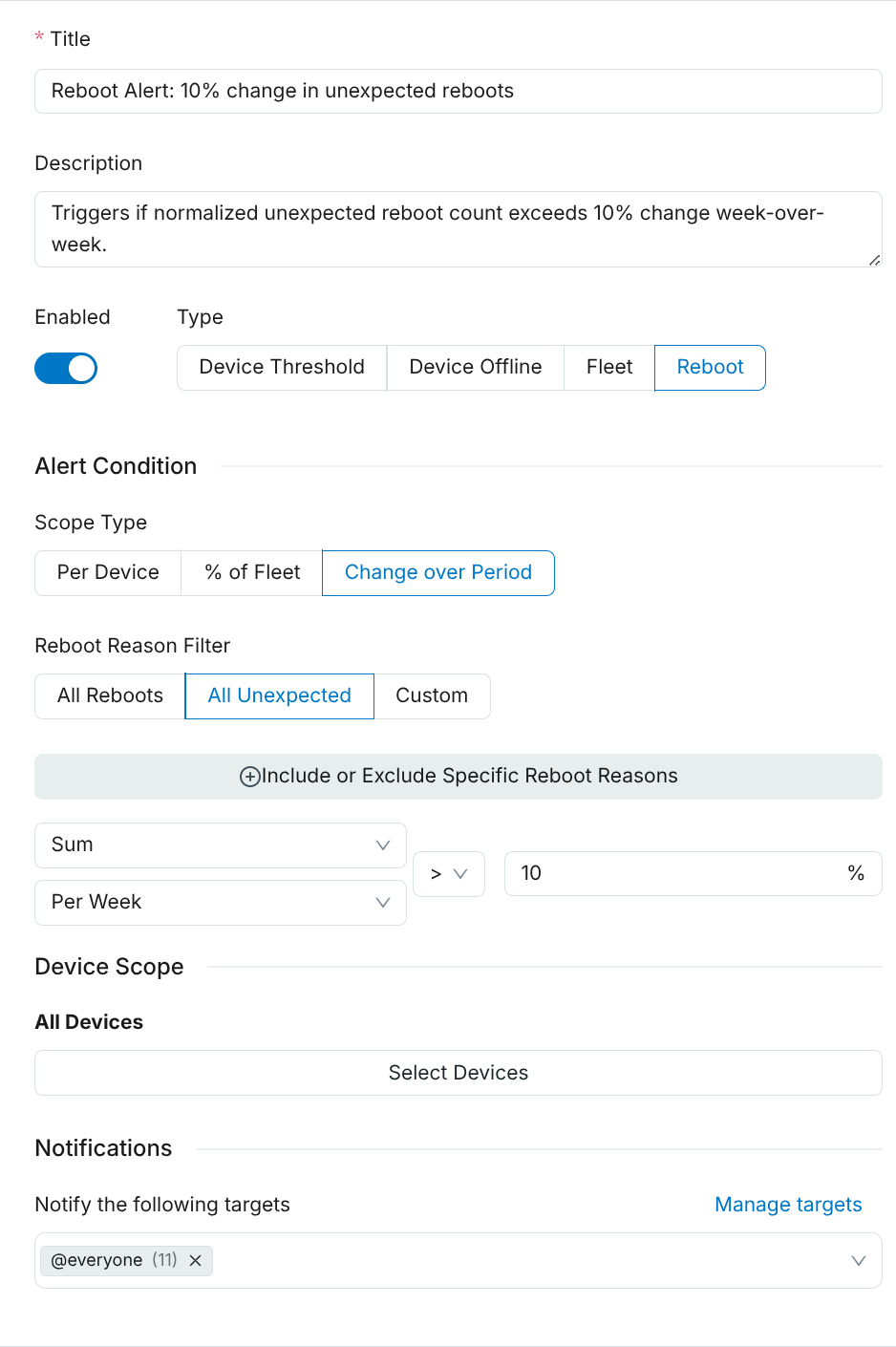
Three alert modes are supported:
- Per-device: Triggers when a single device reboots more than N times within a configurable time window.
- Fleet percentage: Triggers when a configurable percentage of your fleet exceeds a reboot count threshold.
- Change-over-period: Triggers on week-over-week or month-over-month changes in reboot count, useful for catching regressions introduced by a new firmware release.
You can filter by Reboot Reason to focus on the reboots that matter most:
- All: Alert on any reboot.
- Unexpected only: Alert only on reboots that were not clean shutdowns (e.g. watchdog resets, hard faults).
- Custom: Select a specific set of reboot reason codes to include.
Notifications can be routed to email, Slack, or webhooks using the standard alert notification targets.
Creating a Reboot Alert
- Click Alerts in the sidebar, and Create Alert in the top right.
- Provide a Title and optional Description.
- Select Reboot as the Alert Type.
- Choose the Alert Mode: per-device, fleet percentage, or
change-over-period.
- For per-device: set the reboot count threshold and the time window.
- For fleet percentage: set the percentage of devices that must exceed the threshold and the time window.
- For change-over-period: choose the comparison period (week-over-week or month-over-month) and the percentage change that should trigger the alert.
- Optionally, select Devices to scope the alert to a specific cohort, segment, or set of devices.
- Optionally, set a Reboot Reason filter to restrict which reboot types count toward the threshold.
- Select the notification targets and configure when to receive notifications.
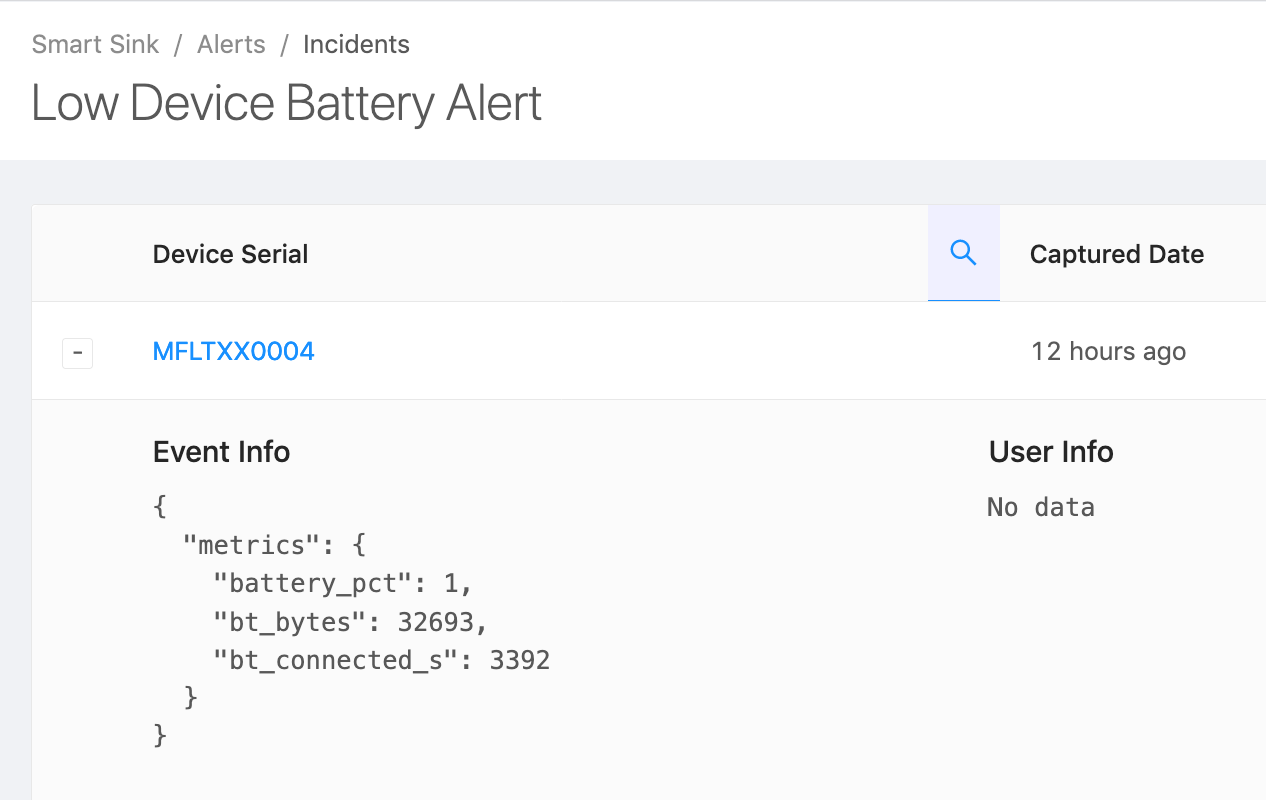
Device Alert Incident Details UI
Once the Alert is set up, Memfault will watch for Events matching the criteria specified. If it finds any, it will create Incidents, which can be found by clicking on the Alert entry in the Alerts table. Note: only Device Alerts have incidents. Fleet Threshold Alerts do not have incidents.
Expect alerts to be delivered in the UI almost immediately under Incidents. Navigate to Alerts and select the Alert you want. Incidents are listed per Device.