Measuring Fleet Reliability With Stable Hours
Device operators commonly struggle to understand the patterns of failures in the field, especially those managing thousands of devices. Attributing failures to specific changes, such as publishing a new firmware update, releasing a hardware revision, or enabling a new feature is even more difficult.
Devices also have a wide range of measurable failures. If the device is a smart lock, a failure can be the deadbolt failing to retract, a firmware fault, or a Wi-Fi disconnection. All of these failures could be critical to understanding the reliability of active devices.
In this guide, we will discuss how to measure device reliability and stability by defining a metric called stable hours and learn how to collect this metric using Memfault. Stable hours is a measure of the number of intervals with crashes over a span of time. With this metric in place, you can easily determine whether a particular firmware update or feature caused a regression in device stability.
Reliability Engineering Background Material
Before explaining how to use Memfault to measure fleet reliability via stable hours, we will discuss a commonly known metric from reliability engineering, Mean Time Between Failures.
Mean Time Between Failures
One frequently used reliability metric is Mean Time Between Failures (MTBF)1. A simple but imprecise definition of MTBF is the following:
Using an exponential distribution to model random component failures yields a more precise definition of MTBF. For more information on the probability theory behind MTBF, please see the resources linked in the footnotes below. The key insight is MTBF is a parameter of the measured population. It should not be used as a single unit's expected lifetime. Using MTBF as a guide, we can define a similar metric for fleet reliability.
Stable Hours and Memfault
IoT devices do not fit the traditional reliability engineering paradigm. A single failure does not render an IoT device non-functional. The failures encountered with firmware are generally deterministic, not random. MTBF provides a good place to start, but we have found there is a more suitable measure of reliability for IoT devices.
Stable hours is the metric Memfault uses for this task. Stable hours provides insight into fleet reliability across any change to the fleet. Mobile and web applications use similar metrics like crash-free users2 or crash-free sessions3. These metrics count crashes across a total number of users or sessions. For IoT devices though, reliability changes are best observed over intervals of time. We need to define what marks an hour as crash-free before completing our definition of stable hours.
Defining Unexpected Reboots
To determine when a stable hour occurs, we must classify reboots as either unexpected or expected. Expected reboots occur through normal use, such as a device resetting before a firmware update, or a user shutting off the device. Failures such as assertions, watchdog expirations, power brownouts, and more are would be classified as unexpected reboots. The SDK's reboot reason tracking subsystem4, 5, 6 provides this capability automatically. When tracking stable hours, it is very important to classify reboot reasons as precisely as possible. Please see the reboot reason subsystem page for more details on your platform.
Defining Stable Hours
To start, we use our configured Heartbeat interval, typically one hour, as the defined length of time. Next, we collect the total number of intervals received from all fleet devices. From these intervals, we count the intervals that contained an unexpected reboot. Finally, we can calculate the percentage of Heartbeat intervals in which no crashes occurred. Here is the formula:
We use a percentage to normalize this metric for easier comparison across time periods and versions.
Enable Stable Hours on Your Devices
MCU Devices
The MCU SDK requires version 1.5.0 or higher to collect data for stable hours.
In version 1.5.0 the reliability metric was changed to operational_hours +
operational_crashfree_hours and standardized across Android, Linux, and MCU
SDKs. See the
Memfault Core Metrics
documentation for more details.
Android Devices
The Android SDK requires version 4.10.0 or higher to collect data for stable hours.
Linux Devices
The Linux SDK requires version 1.9.0 or higher to collect data for stable hours.
Viewing Stable Hours On Memfault
The stable hours metric is currently not automatically shown in the Memfault UI. The recommended approach is to create two charts in the Metrics section to display Total Operational Hours and Total Hours With Crashes. With these two charts, stable hours can be manually calculated.
-
Create a chart to track Total Operational Hours:
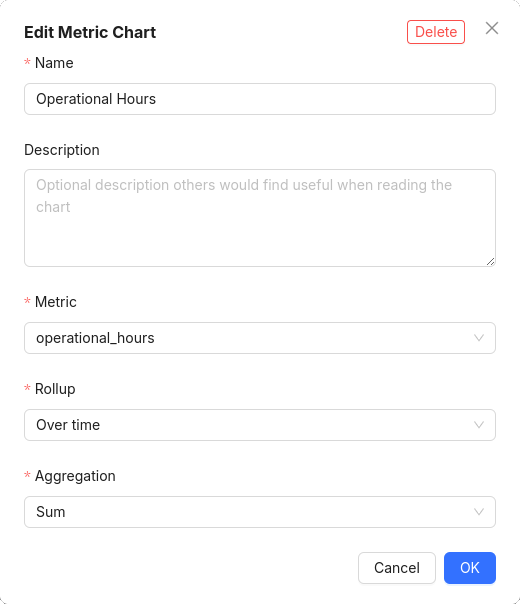
-
Create a chart to track Total Hours With Crashes:
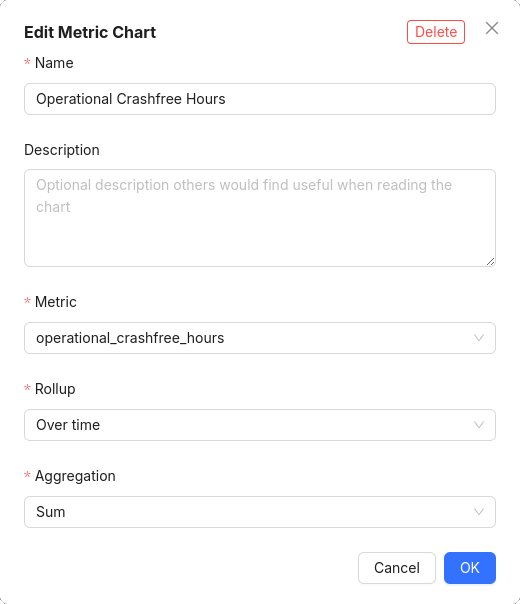
Now that we have our charts, we can calculate % of stable hours using our formula above over each interval.
To simplify things, let's assume our Heartbeat intervals are 1 hour in length and we're interested in a period over 5 days. We have a fleet of 10,000 devices, each operating for 10 hours a day. Over this period, we found that 1500 hours had an Unexpected Reboot.
Following this example, the fleet has a percent of stable hours equal to 99.7%.
If a future firmware update is released, and the stable hours metric drops down to 95%, this would tell us that there is a stability regression in the new firmware.
Stable Hours Example Using Memfault
In this next section, we will walk through some data collected by devices in a fleet to show how stable hours can work in practice.
In this example we have a small fleet that has two software versions. The first version, reliable-fw v1.0.0, has many crashes. Let's calculate the stable hours for this first release. We'll use our data from 1/23.
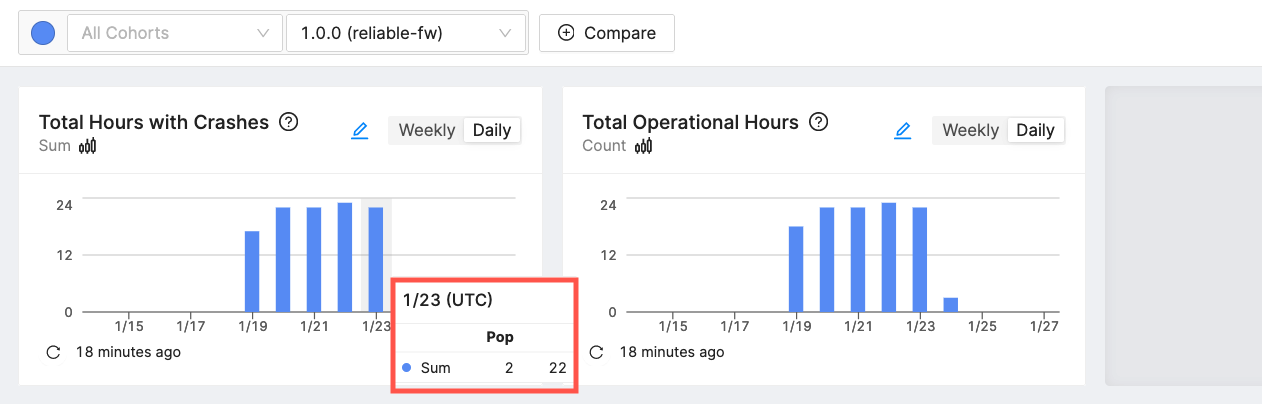
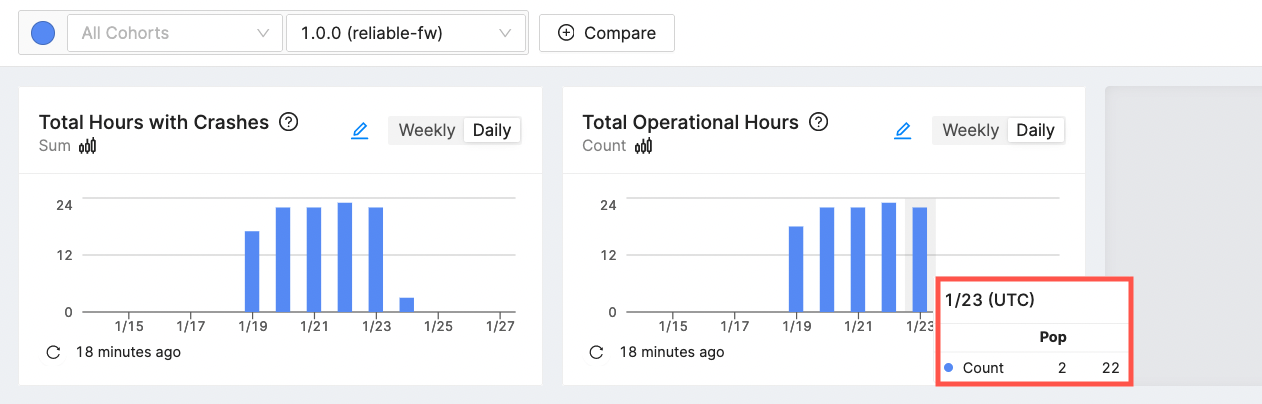
Our devices are hitting a crash ever hour, about as bad as things can get. We use the collected coredumps to determine a fix and release reliable-fw v1.0.1. Here's an update to our data.
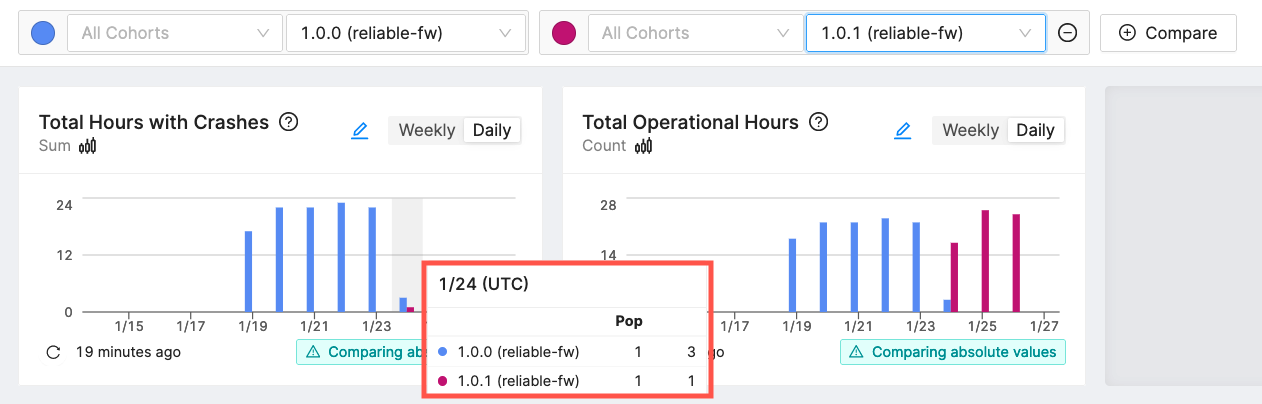
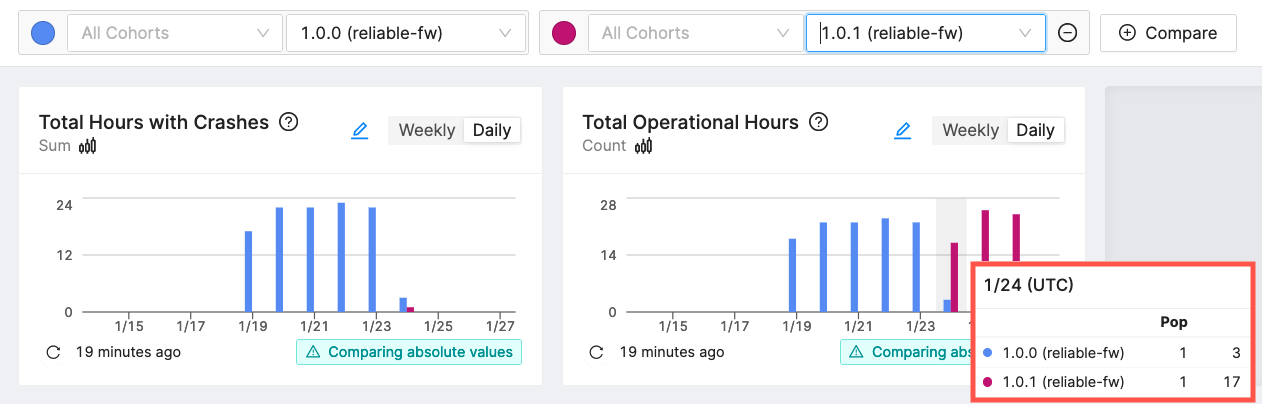
Using the version comparison feature, we can clearly see that our crash count has plummeted and our total hours have remained about the same. For completeness, here is the calculation for the day v1.0.1 was released, 1/24.
Not Just Crashes
The techniques discussed in this article can be applied to any type of failure. Here are some examples:
- Bluetooth disconnections
- Failing to open/close a lock
- Sensor read failures
- Your device's unique operational condition
The key to measuring these is to measure the number of intervals with a failure, and the total number of intervals collected, and run these through the same formula.
If you have any questions about how you can calculate a similar metric to stable hours for your own devices or firmware, feel free to reach out to us.