Manually Uploading Linux Diagnostic Data
Through the Linux SDK / memfaultd
When configured with a Memfault Project Key, memfaultd
will by default, automatically start uploading device diagnostics information
into Memfault.
During development, you can use memfaultctl sync to manually trigger an
upload. We recommend enabling Developer Mode when doing so.
Using the Memfault CLI
This guide assumes the Memfault CLI tool installed. If it is not installed it yet, please follow the installation instructions.
memfaultd bundles and uploads device diagnostics information in MAR files.
These MAR files can also be uploaded using the memfault CLI tool. Note this is
a different tool than memfaultctl. The memfault CLI tool is typically not
used on the device itself, but rather on developer or CI machines.
The following examples will use an Organization Auth Token. Please refer to the Memfault CLI Authentication section for more information about the different forms of authentication.
Uploading a MAR file
A Memfault Archive File (MAR) is an archive format that is generated by
memfaultd containing many files in a compressed ZIP archive. The rationale
behind creating and using a bundle containing many files is:
- To minimize data bandwidth and HTTP requests for cellular devices and minimize CPU and power consumption for battery-operated devices.
- To make it easier for customers to send large amounts of device-generated data to Memfault.
- To be able to send Memfault-specific data alongside the raw files that the operating system creates, such as Linux Coredumps.
- To be able to associate data within a MAR file to multiple devices.
To upload a MAR file that is located at, for example /path/to/device-data.mar,
run the appropriate command:
The Software Type, Software Version, Hardware Version, and Device Serial parameters of the CLI command below should match that of the device which generated the MAR file.
$ memfault \
--org-token <Memfault-Project-Key> \
--org <ORG_SLUG> \
--project <PROJ_SLUG> \
upload-mar /path/to/device-data.mar
--software-type <DEVICE SOFTWARE TYPE>
--software-version <DEVICE SOFTWARE VERSION>
--hardware-version <DEVICE HARDWARE VERSION>
--device-serial <DEVICE SERIAL NUMBER>
Uploading Diagnostic Data via API
Please consult the HTTP API Upload documentation for details on how to upload files to Memfault using the API.
Using the Memfault UI
memfaultd will automatically capture coredumps and upload them to Memfault.
However, if you have a coredump that was captured outside of memfaultd, you
can upload it manually through the Memfault UI.
Manually capturing a coredump
To manually capture a coredump, you can use one of these techniques:
- You can use the
gcoreprogram (part of the GDB package) to capture a coredump from any running program, given its PID. This program is a script that attaches GDB to the program with given PID and runs the gcore or generate-core-file GDB command. - You can let the kernel capture a coredump of a program:
# Configure the kernel to create a file called "core.elf" upon coredumping:
sudo tee -a /proc/sys/kernel/core_pattern &> /dev/null <<< core.elf
# Ensure unlimited coredumps can be captured:
ulimit -c unlimited
# If an process crashes now, a coredump will be captured automatically. To
# trigger a coredump manually (without a crash), send the SIGQUIT signal:
kill --signal SIGQUIT $PID
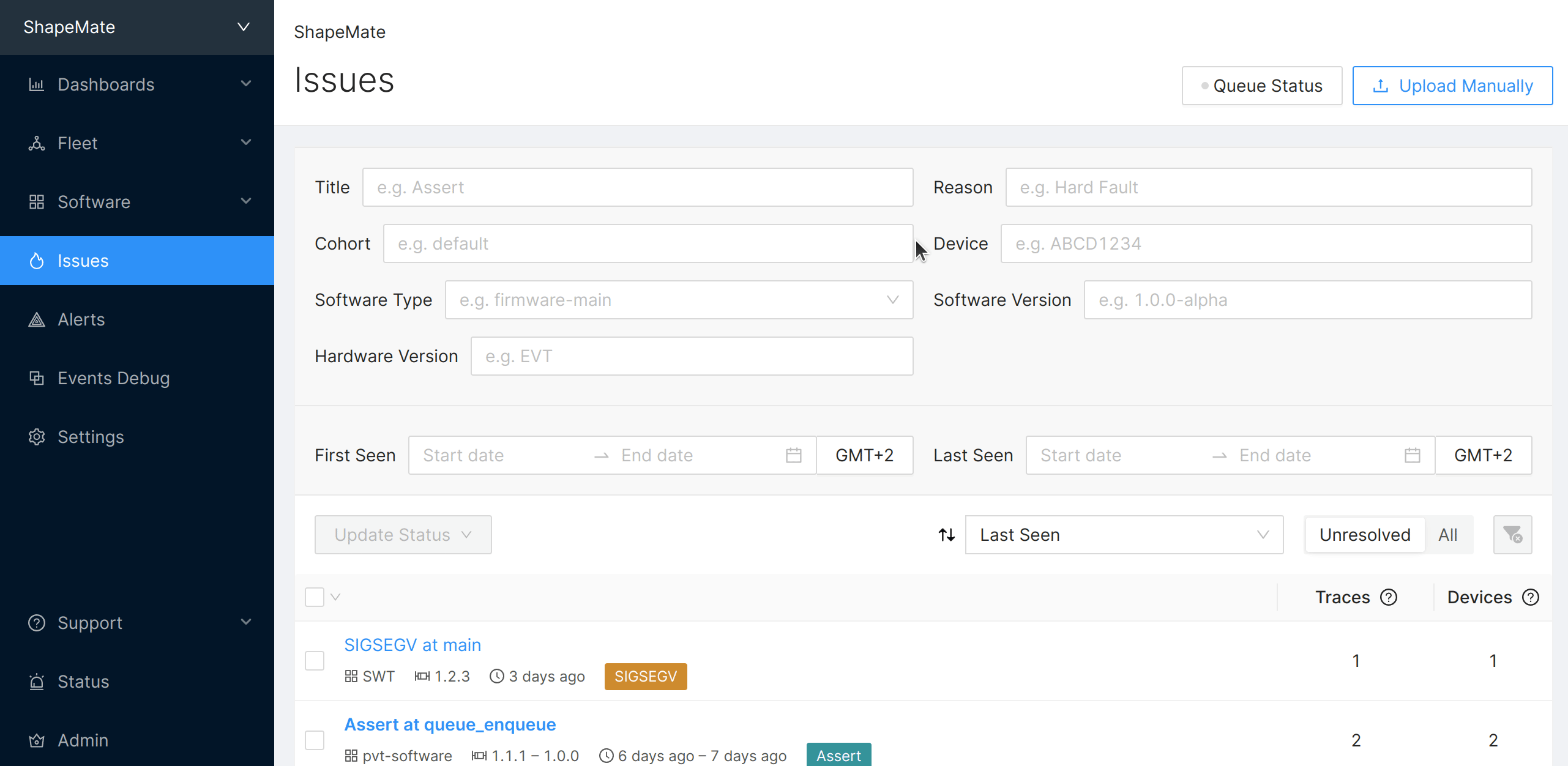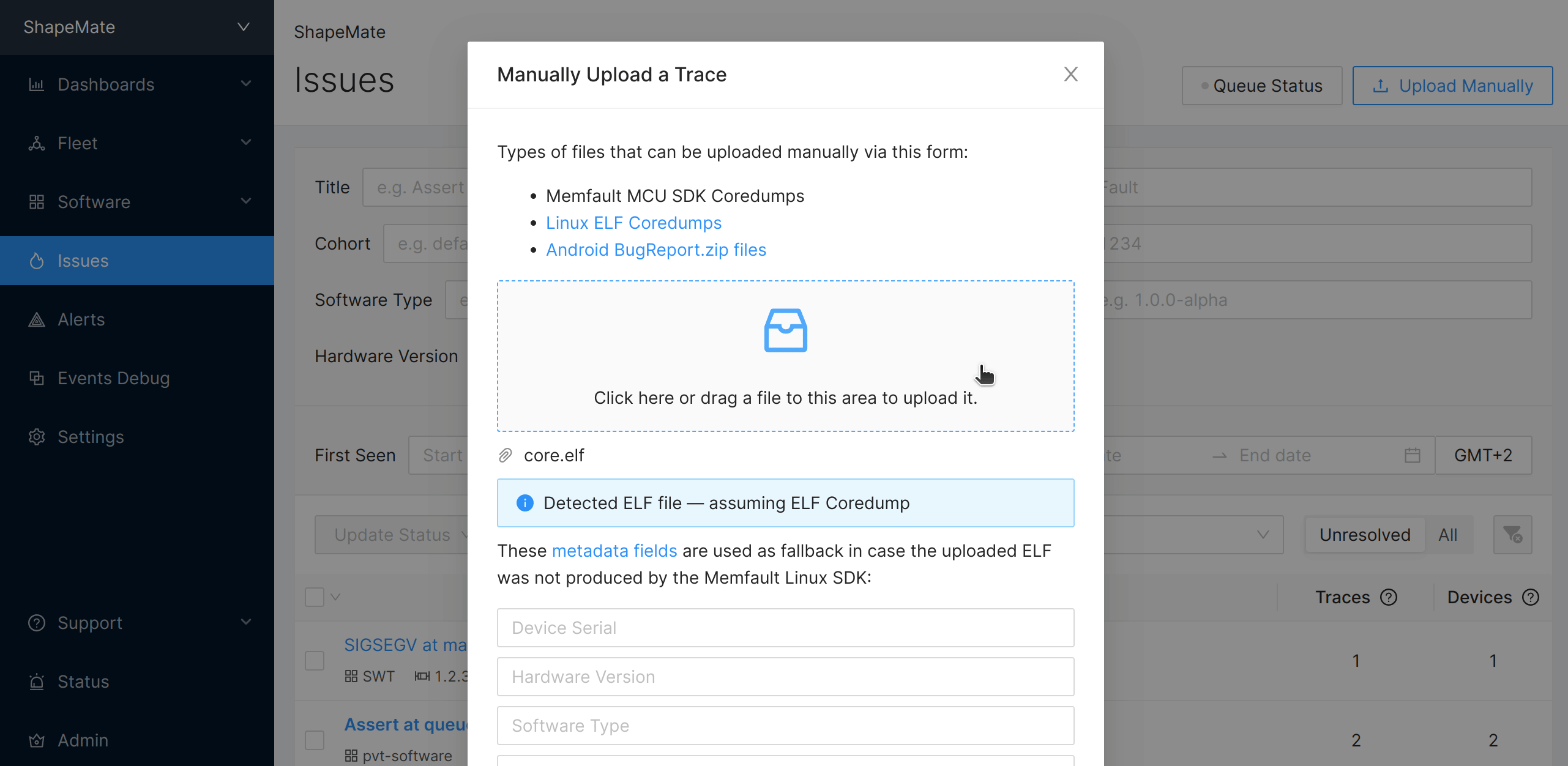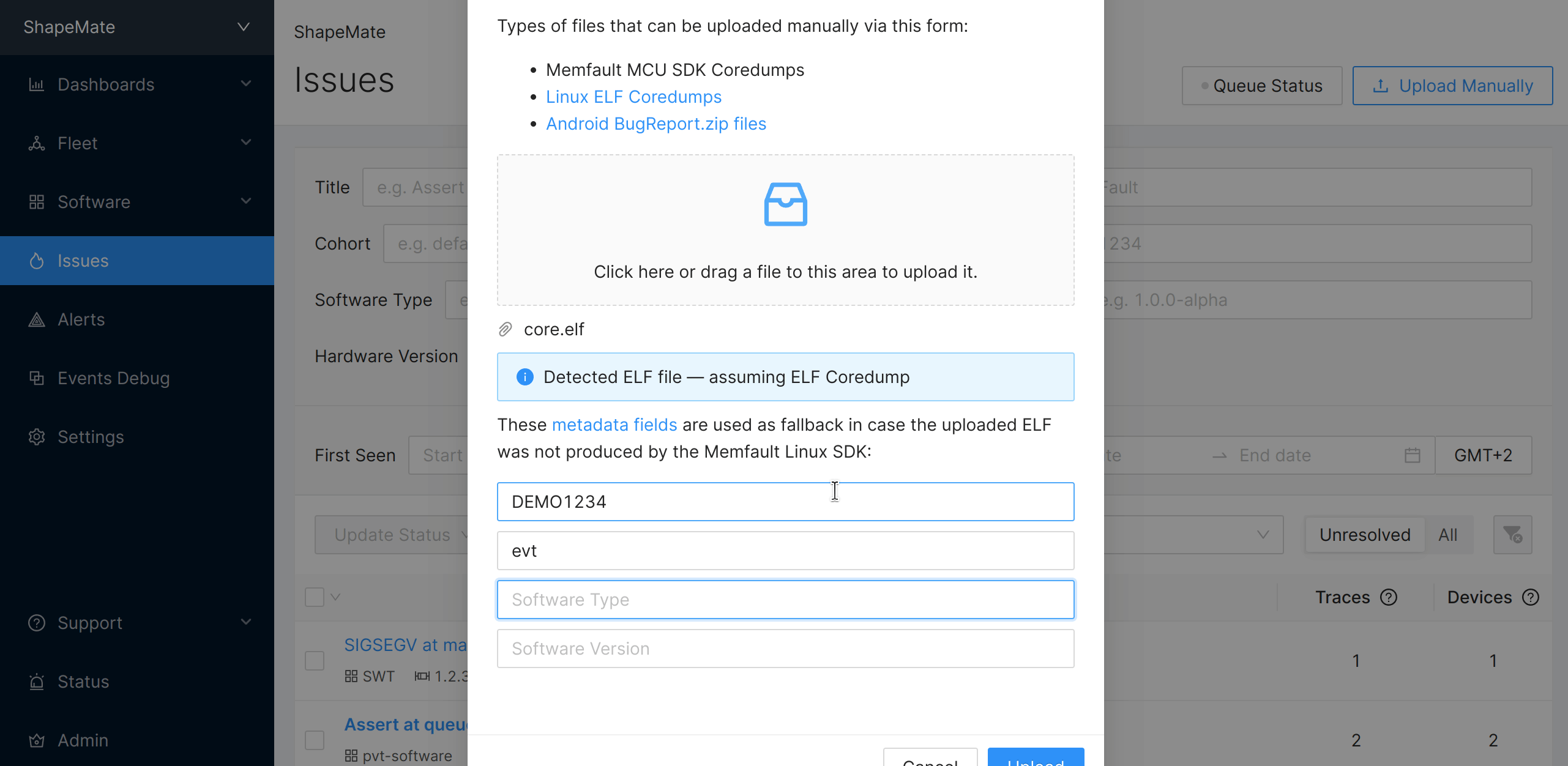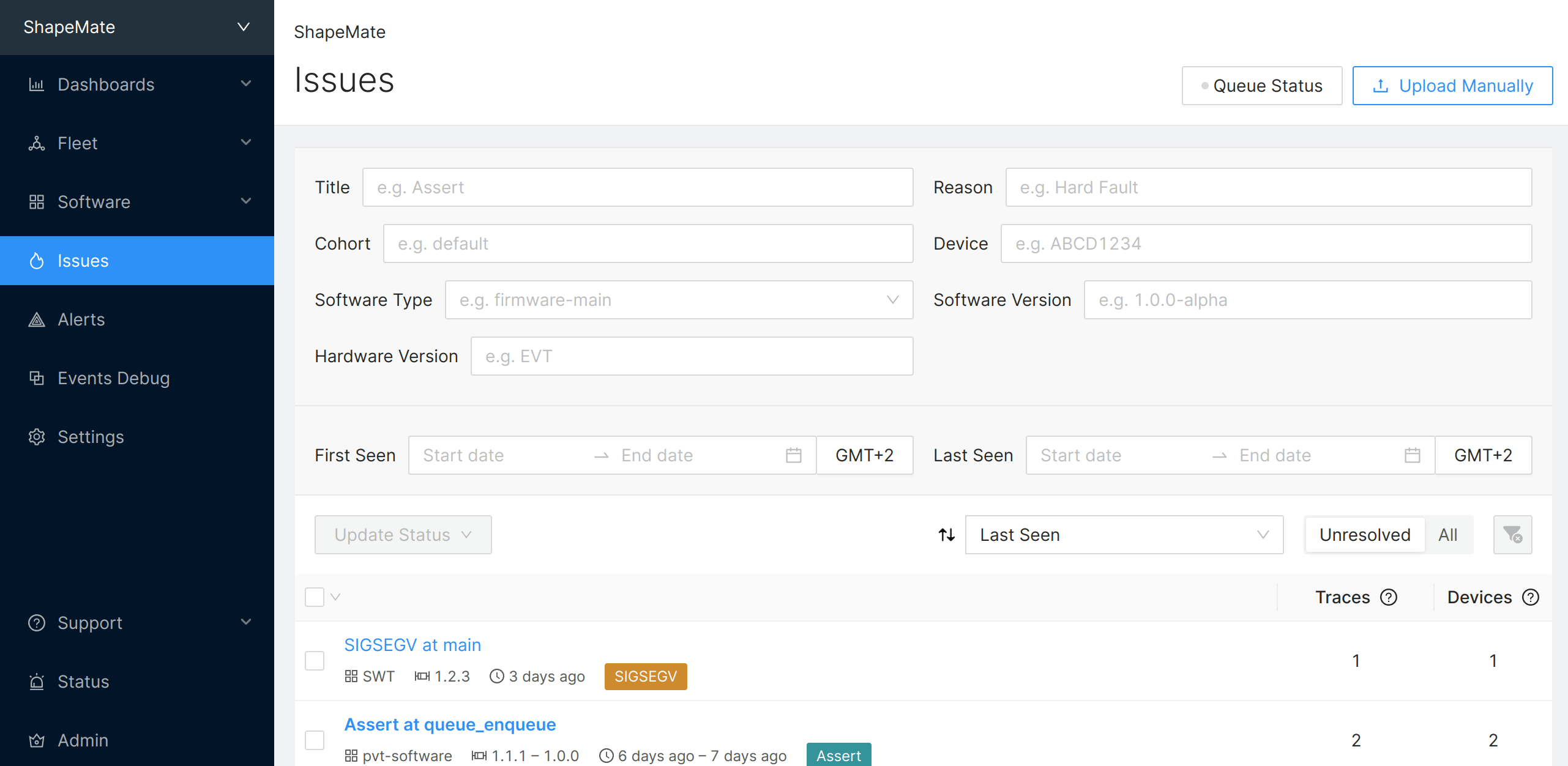
Uploading a coredump ELF file via the UI
Once you have captured a coredump ELF file from a device, you can upload it via the Memfault UI by navigating to the Issues page and selecting Manual Upload.
You will need to provide metadata of the device that
generated the coredump in the UI form. In case the coredumps was captured by the
Linux kernel or GDB, this metadata is required. In case the coredump was
captured by memfaultd, this will be ignored (because memfaultd already adds
metadata into the ELF when capturing the coredump).
Note that you will also need to upload symbol files for binaries that were loaded by the program of the coredump. For Yocto-based systems, you can find instructions on uploading symbol files here.
Uploading a MAR file using the Memfault UI
MAR files (.mar) can also be uploaded via the same Manual Upload flow
described above.