Android Logging
Memfault Caliper collects logs from every logcat buffer. Logs are uploaded when they overlap a Trace Event, and are associated with the trace.
Log files collected by Caliper are scrubbed on-device before being uploaded. See Data Scrubbing
Logs can also be collected via bug reports - but this is not recommended.
Configuration
Bort will process the stored logcat logs for issues, which can be configured from the Project Settings page under Data Sources.
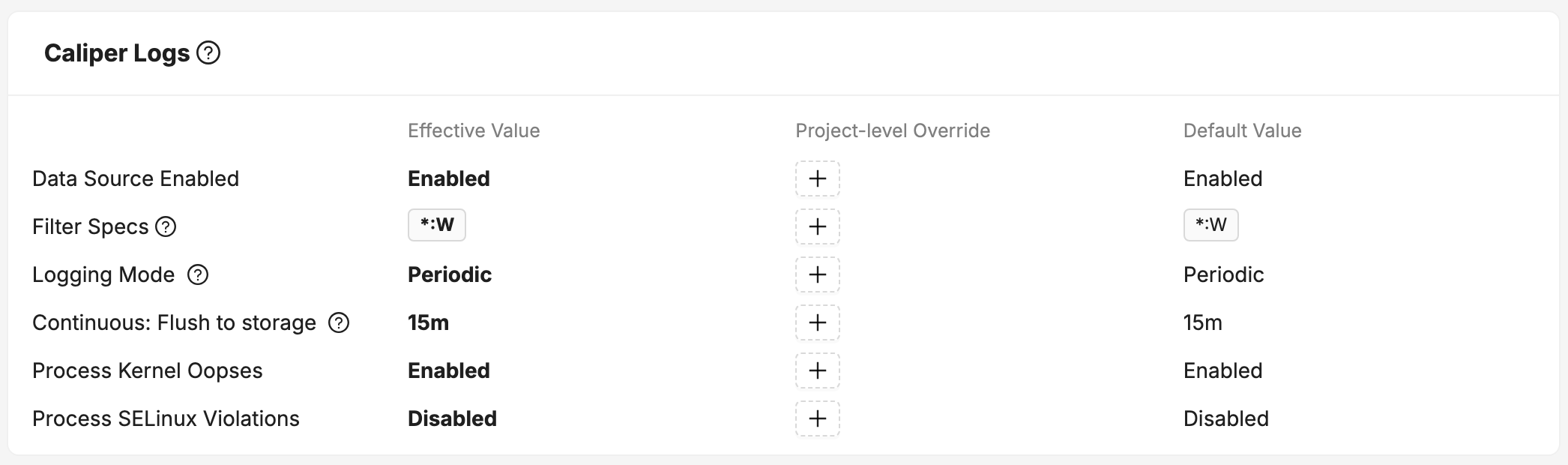
Kernel Oopses
Android Kernel Oops are Linux OS errors. They are sometimes non-fatal, but can also precede a fatal Kernel Panic.
SELinux Violations
Android SELinux Violations are records of denials to access resources from any running application.
Caliper Logging Modes
Periodic
The default behavior. Bort will collect logcat from all buffers at a regular interval (15 minutes).
In the case of log buffer expiry (if log buffers are too small, or if the device has particularly spammy logging), it is possible that some logs may be missed.
Continuous
This mode is designed to avoid missing logs due to buffer expiry.
The MemfaultDumpster system service continuously reads from all log buffers.
--wrap mode is used, so that logs are only written to disk on buffer expiry or
timeout (i.e. the service is not continuously writing logs to disk).
The Flush To Storage setting controls the maximum period before logs are flushed to disk if no buffers have expired. This does not affect how log files are chunked for upload.
Log upload works the same way as for Periodic.
Automatic Log Collection
Memfault collects logs either periodically or continuously, but not all logs that are collected by the SDK will be uploaded.
Out of the box, Memfault will only mark logs for upload if that log covers "events of interest", such as crashes. This ensures that we can surface the relevant context at the right time, to aid debugging that issue.
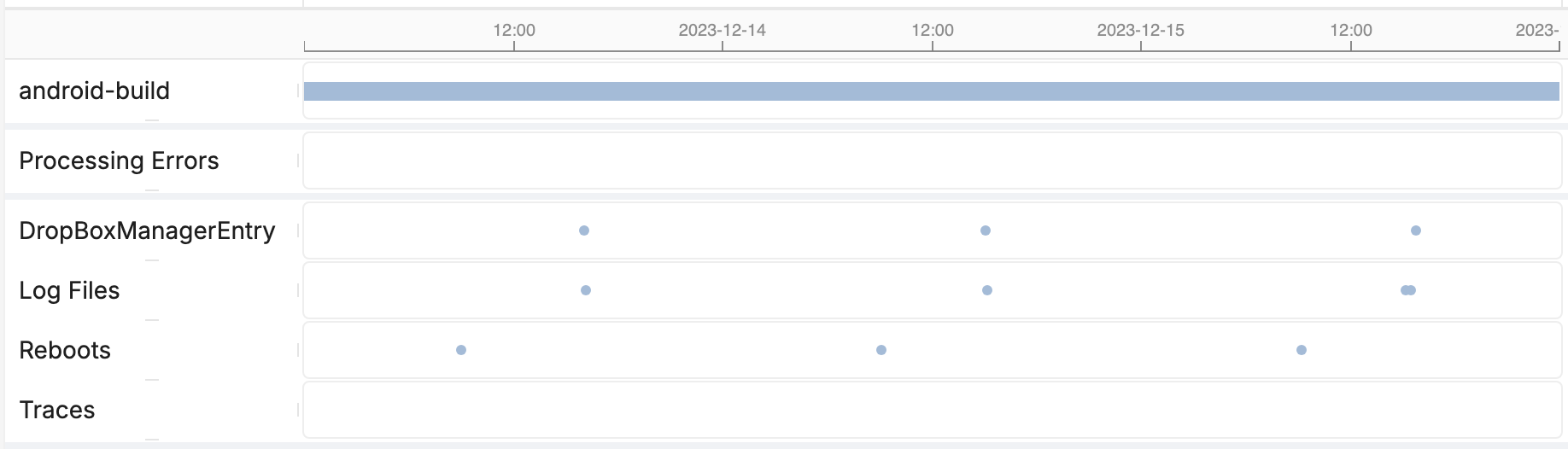
Logs are uploaded only when events of interest are detected.
With Fleet Sampling, it is also possible to upload logs that were collected in the near past:
- If we turn on the debugging fleet sampling aspect for a device after an event of interest, the device will upload existing logs marked for upload collected before that the aspect was enabled.
- If we turn on the logging fleet sampling aspect, then all logs, both in the near past and moving forward, will be uploaded.
When logs are captured, the timezone of the logs are set to UTC rather than device timezone. You will notice this when downloading the raw logs from a device's logfiles tab. If you view the logs via the Memfault Log Viewer, they will be displayed in the timezone currently selected in the Timezone Selector (default: browser timezone).
Converting logs into metrics
This feature is supported in the Bort SDK from version 5.2.0.
You can use Bort to convert logs into metrics. Specific patterns in log messages will be captured directly on the device and efficiently transformed into metrics. Edge processing of logs is much more efficient than trying to upload all the logs and process them in the cloud.
This enables:
- Monitoring and alerting on Kernel and System logs,
- Monitoring and alerting on application logs when it's not convenient or easy to instrument the application with StatsD metrics directly,
- Monitoring for security events and reporting them.
Create rules on the "Data Sources" screen - they are entered using json.
When creating a rule, you must specify:
- A rule type - the only rule currently supported is
count_matching, which will increment a counter each time the pattern is found (and display the match on Device Timeline using HRT). - A logcat tag - only messages with this tag will be searched for matches (this avoids running regexes on every single log line). This must be an exact match (i.e no wildcards are allowed).
- A log level - only messages >= this level will be searched for matches.
- A pattern - this is a regex which will be checked against every log line matching the tag/level constraints. Any match against this regex will generate a metric.
- A metric key - this is how the metric will be named. Optionally, this key can contain placeholders to change the name based on the search result (see below).
Example
| Rule Property | Value |
|---|---|
| Rule | count_matching |
| Tag | MyApp |
| Level | I |
| Pattern | Error processing input |
| Name | input_processing_error |
We would input this rule using the following json:
{
"rules": [
{
"type": "count_matching",
"pattern": "Error processing input",
"metric_name": "input_processing_error",
"filter": {
"priority": "I",
"tag": "MyApp"
}
}
]
}
If we apply this rule to the following logs:
2024-10-17 10:15:54.326 1753-1753 MyApp com.x.y E Error processing input: code 33
2024-10-17 10:16:00.002 1947-1947 MyApp com.x.y D Error processing input: code 22
Then this will result in one metric being generated with the key
input_processing_error (the sum of this will be uploaded in each report as
input_processing_error.count). When viewing HRT on the Device Timeline, the
matching string will be visible in the event popover.
If we want to vary the metric key based on the search result, then we can do
this by setting the metric key to input_processing_error_$1. This will replace
each $n with the match group of index n from the pattern. For example:
{
"rules": [
{
"type": "count_matching",
"pattern": "Error processing input: code (\\d+)",
"metric_name": "input_processing_error_$1",
"filter": {
"priority": "I",
"tag": "MyApp"
}
}
]
}
Will generate a metric with the key input_processing_error_33, from the input
above.